Application Inference Profiles for AWS Bedrock foundation model cost and access management


One of the gaps identified early in using Bedrock was the lack of cost control and access management for on-demand inference requests. While CloudWatch records basic token utilization and latency metrics, there was little to no visibility into ad hoc requests made from the Bedrock Playground, or when using Bedrock APIs exposed in boto3... until now.
In November, AWS introduced application inference profiles as a bridge to cover this relatively important gap. The value proposition, described from their blog announcing the feature's general availability:
AWS has launched a capability that organization can use to tag on-demand models and monitor associated costs. Organizations can now label all Amazon Bedrock models with AWS cost allocation tags, aligning usage to specific organizational taxonomies such as cost centers, business units, and applications.
This also facilitates better service integrations; because an application inference profile is a resource with an ARN, it can be managed with RBAC and account level policies, and wired to alerts and budgets. No more rogue ad hoc inference requests! (assuming your other policies are in place).
Creating an Application Inference Profile
Creating an app inference profile is straightforward, but there is a bit of nuance to understand.
import boto3
session = boto3.Session(profile_name='YOUR_AWS_PROFILE')
bedrock = session.client('bedrock')
bedrock_runtime = session.client('bedrock-runtime')
inference_profile_arn = bedrock.create_inference_profile(
inferenceProfileName='Titan-Premier-Inf-Profile',
description='App inference profile for Titan Premier clients',
modelSource={
'copyFrom': 'arn:aws:bedrock:region::foundation-model/fm-identifier'
},
tags=[
{
'key': 'owner',
'value': 'Someone'
},
{
'key': 'project-id',
'value': 'ABC123'
}
]
)
After creating a session, create_inference_profile is called (which does exactly what it says - creates the application inference profile) and returns an ARN.
Note:
- app inference profiles can only be created using the SDK
- As far as I can tell, app inference profiles are not visible anywhere in Bedrock or other console views except for the Bedrock Playground. This can make discovery of existing app inference profiles difficult. For clients or apps that need to share or identify an existing profile resource, assuming correct permissions, a call to retrieve existing app inference profiles should be made using the list_inference_profiles API call with a
typeEqualsargument value of APPLICATION:bedrock.list_inference_profiles(typeEquals='APPLICATION')
This will return just application inference profiles; leaving the argument out causes system inference profiles to be returned as well (as of this writing there are 16 of them) - Specifying the ARN of a foundation model or a cross-region inference model in the
modelSourcetagged union structure provides the app inference profile with the same configuration available from the target model, so you get multi-region support "for free" if you use a model that supports it (and costs will accrue in the primary region)
Using An Application Inference Profile
Once the discovery hurdles are understood, using the profile is as simple as replacing the modelId with the profile's ARN for any inference calls made via Converse or InvokeModel APIs. Because tags are applied during creation, any calls using the profile will appear in Cost and Billing Reports when filtering by tag. Building on the first part of the code:
# use the ARN in your inference request
response = bedrock_runtime.converse(
modelId=inference_profile_arn,
system=[
{
"text": "You are a helpful AI assistant."
}
],
messages=[
{
"role":"user",
"content": [
"text": "List 3 differences between Japanese and American baseball."
}
]
)
print(response)
Guidance from AWS suggests using Parameter Store to hold the ARN and retrieve it using get_inference_profile and passing the ARN or the profile ID. Depending on how the profiles are created though, the ARNs may change.
Finally, for service roles, access and usage can be constrained by specifying resources in an IAM policy, in the same way access to the foundation model is managed:
"Resource": ["arn:aws:bedrock:*:application-inference-profile/*"]
This last part is important, because applications and users are not compelled to use the available profile unless constrained by policy!
Validating the outcome
I found the easiest way to validate the inference profile was to just make an inference request using the ARN and inspect CloudWatch logs and Cost Explorer under Billing and Cost Management.
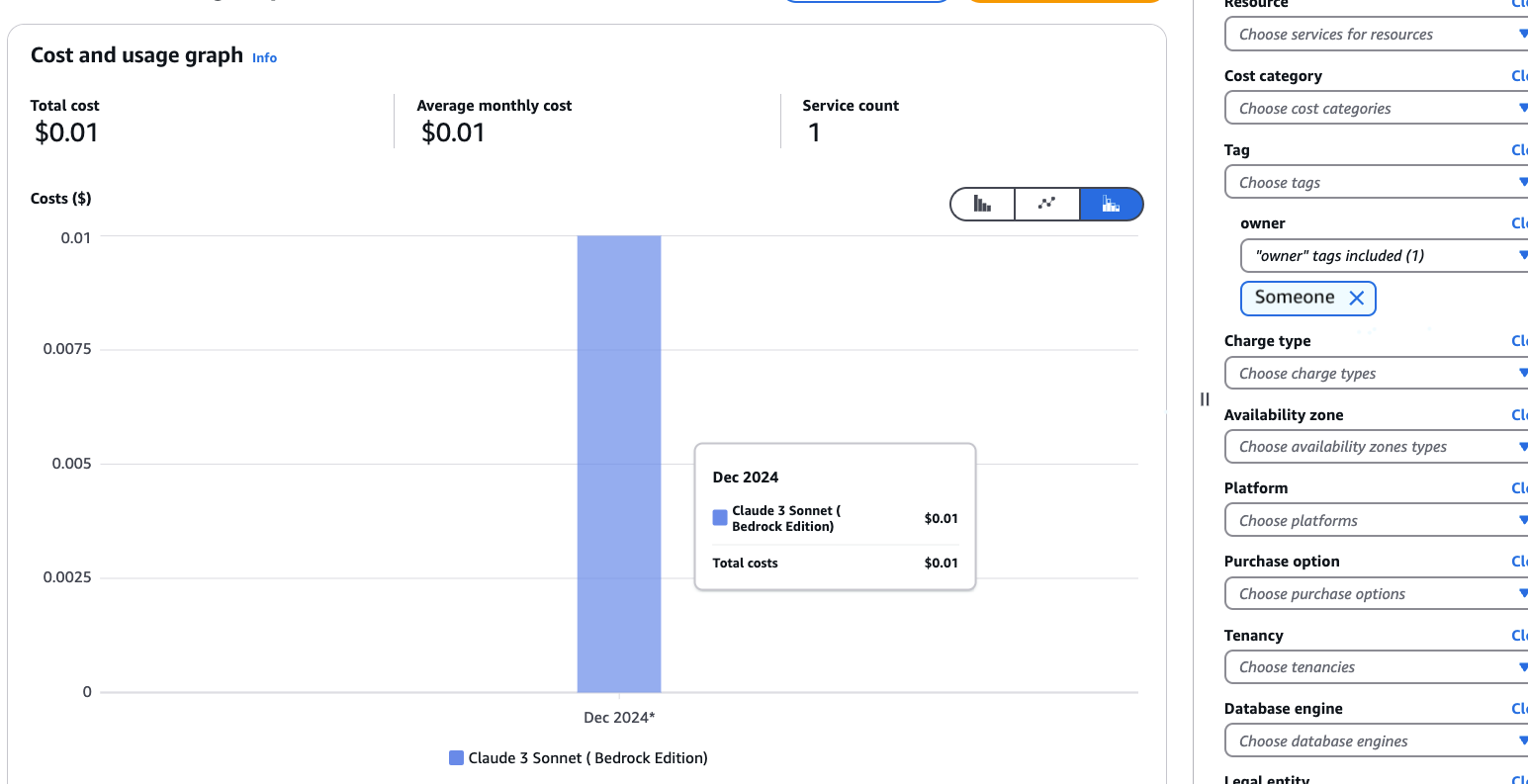
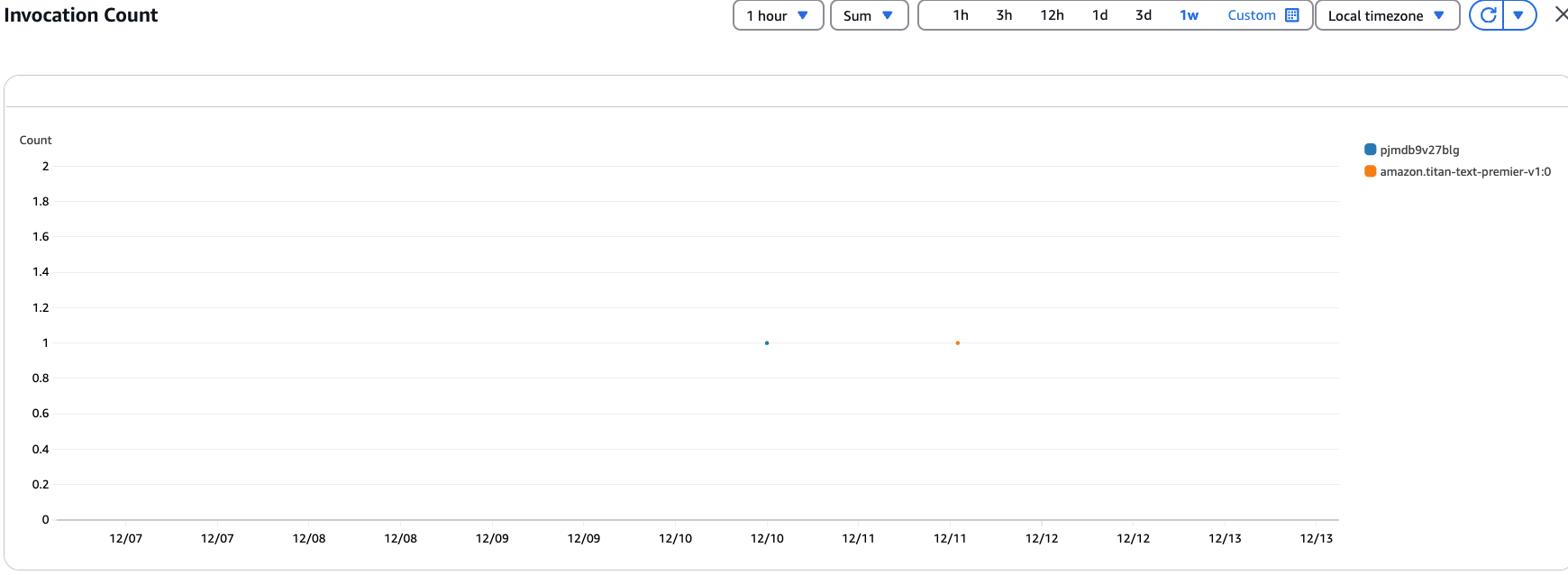
Heres where I noticed in Bedrock's automatic dashboard that the model name is replaced by the ID of the profile. I'm not sure I understand the reason or limitation here, but this feels to me like a discoverability issue again and I hope this eventually changes to use the applied inference profile name (which is visible when selecting profiles in Bedrock Playground). It also makes it difficult to track individual usage based on application, which would be useful to understand which applications are using most of available quotas if multiple apps share the profile.
Bedrock Playground does show the name of the profile when selecting a target FM that has one created against it:
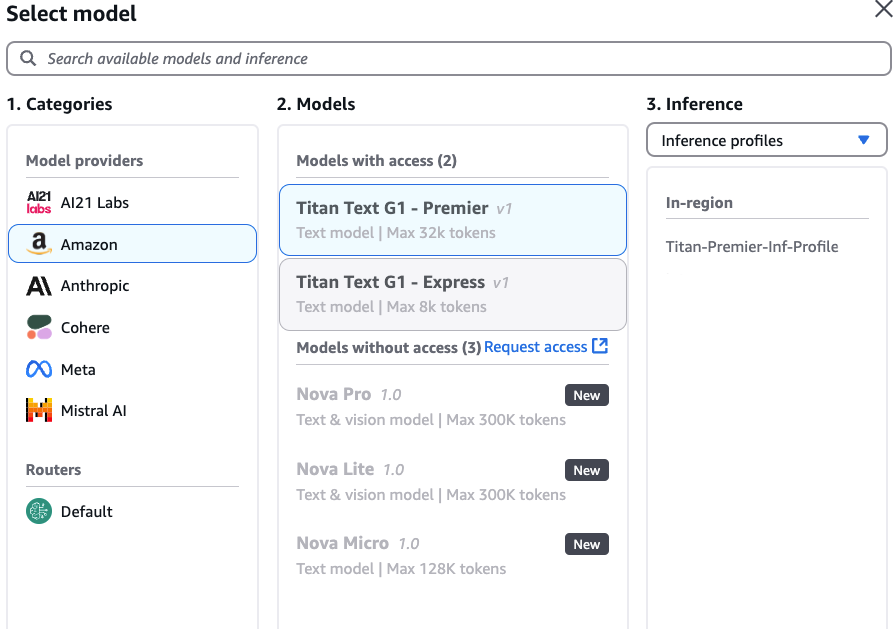
With a validated profile, applications are ready to use the profile and should start reporting cost metrics immediately!
Sources and additional reading:


